Training the Model¶
Before training a model, the dataset must be created as described in the dataset section.
The model can then be trained using a ui.json interface in Geoscience Analyst. The interface is divided into two tabs: General and Optional parameters. The General tab is shown in figure_train_uijson below.
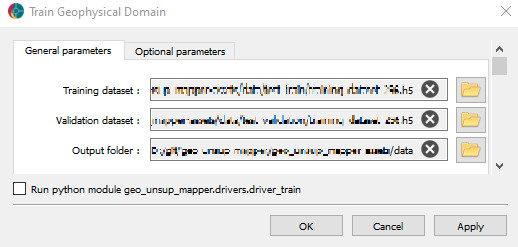
General tab of the training interface.¶
Three options are available in this tab:
The Optional tab is shown in figure_train_optional_uijson below.
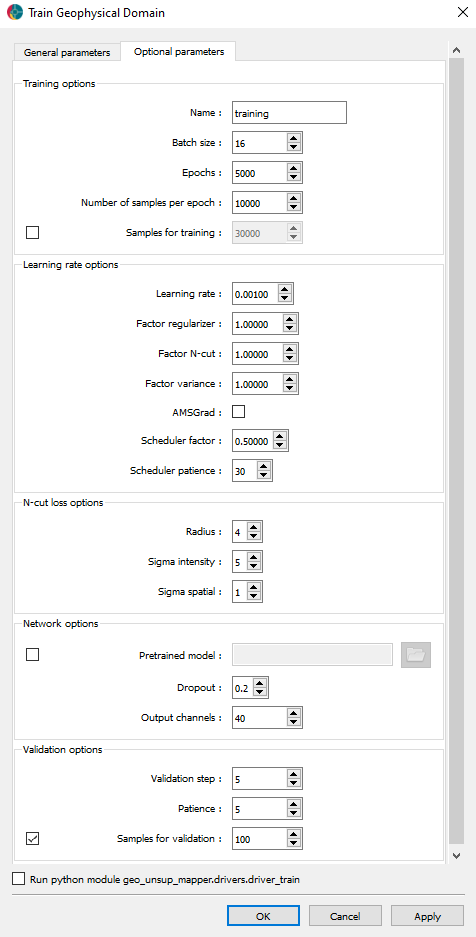
Optional tab of the training interface.¶
The tab is divided into different sections, containing several options to set the training parameters.
Training options
Name: The name of the model to train.
Batch size: The number of samples to use in each batch.
Epochs: The number of epochs to train the model.
Number of samples per epoch: The number of samples to use in each epoch.
Samples for training (optional): Randomly select a given number of samples from each dataset. This avoids data imbalance if one layer contains many more tiles than another.
Learning rate options
Learning rate: The initial learning rate of the optimizer (the Adam optimizer).
Factor regularizer: The regularizer factor for the input block (see the Model section).
Factor N-cut: The factor applied to the N-cut loss (see the Model section).
Factor variance: The factor applied to the variance loss (see the Model section).
AMSGrad: If checked, the AMSGrad optimizer is used.
Scheduler factor: The factor applied to the learning rate scheduler. The learning rate scheduler used is the ReduceLROnPlateau method.
Scheduler patience: The patience of the learning rate scheduler.
N-cut loss options
Radius: The radius for the N-Cut loss (see soft n-cut loss paper).
Sigma 1: The intensity sigma for the N-Cut loss (see soft n-cut loss paper).
Sigma 2: The spatial sigma for the N-Cut loss (see soft n-cut loss paper).
Network options
Pretrained model (optional): The path to a pretrained model to use.
Dropout: The dropout rate to use in the network.
Output channels: The number of output channels of the network generator.
Validation options
Validation step: The number of epochs between each validation.
Validation patience: The patience of the validation.
Samples for validation (optional): Randomly select a given number of samples from each dataset. This avoids data imbalance if one layer contains many more tiles than another.
Once you have set all the parameters, you can start the training by clicking on the OK button. The training will begin, and the model will be saved in the folder specified in the General tab. We highly recommend using a GPU to train the model. During training, at each validation epoch, the loss scores, results of the first validation batch, and the state of the model’s weights (as .pt files) are saved in the Output folder.
Training a model is a lengthy process, taking several hours or days depending on the dataset size, the number of epochs, and the computing capabilities of the machine it’s trained on. It also requires an iterative trial and error to find the best parameters for the model.